What if your edge isn’t in finding better data but in building the exact data your hypothesis needs, exactly when you need it?

For years, investment teams have relied on structured datasets as the foundation of systematic strategies. They’re scalable, consistent, and proven. But they also encode a fixed view of the world and markets don’t stand still.
Our latest deep-dive, “From Dataset Consumer to Dataset Creator,” explores how AI is changing that equation, and how teams can start building bespoke microdatasets to uncover new sources of alpha.
Why structured data still matters and where it falls short
Structured datasets work because they simplify complexity. They transform messy, unstructured information into clean, usable signals: scores, labels, and rankings that can scale across entire universes. But that simplification comes at a cost.
Every dataset reflects a set of decisions:
What topics matter
Which entities to track
How events are classified
Over time, those decisions can drift away from reality, as new risks emerge, industries evolve and relationships between sectors change. Structured data doesn’t break, it just becomes less aligned with what’s happening now. And that’s where the opportunity lies.
The shift: AI makes custom data viable
Historically, building your own dataset from raw content was possible, but impractical.
It required curating and licensing large volumes of data, building and maintaining NLP pipelines, solving entity resolution at scale and investing weeks or even months for each idea. Today, that barrier is collapsing.
AI-driven workflows now make it possible to:
Break down hypotheses into searchable components
Retrieve relevant content using semantic search
Automatically map text to companies and assets
Build and test signals in hours instead of weeks
This changes the calculus entirely. Smaller, more targeted ideas (once too costly to pursue), are now within reach.
What is microdataset construction?
Microdataset construction flips the traditional workflow.
Instead of starting with available data, you start with a specific hypothesis and build the dataset around it. The process is systematic:
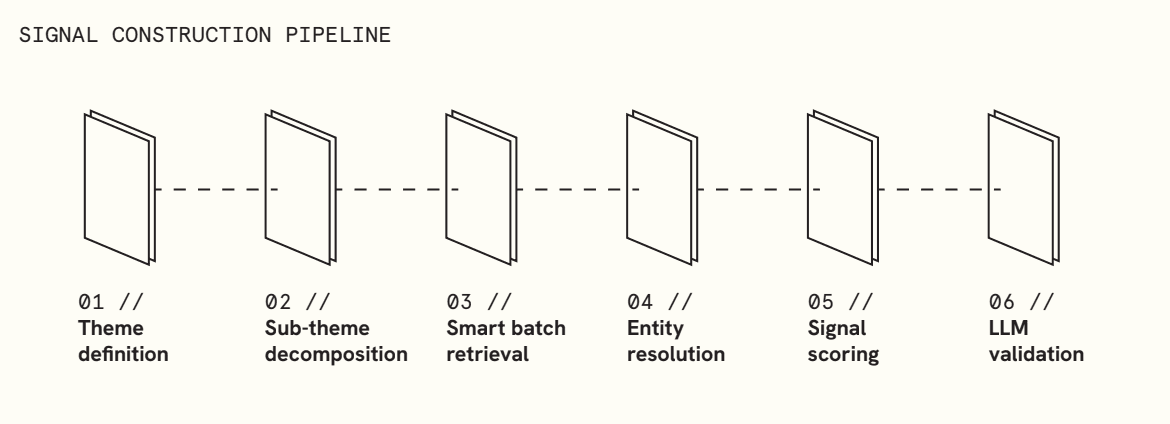
The result is a custom-built dataset, designed to answer a single question and generate a usable signal.
Where the Alpha comes from
The most interesting signals rarely originate from widely used datasets. They tend to emerge at the edges, where existing classifications start to break down, where new or poorly understood events are unfolding, and where coverage across the market is still uneven. These are precisely the areas where traditional data structures struggle to keep up.
Microdataset construction opens up that space. By allowing researchers to build datasets around specific, timely hypotheses, it becomes possible to capture signals that standardised products were never designed to include. It also reduces exposure to crowded inputs, enables faster iteration on new ideas, and, importantly, creates genuinely proprietary data advantages. In this sense, differentiation shifts upstream, into the way the data itself is defined and constructed.
Case in point: the semiconductor shortage
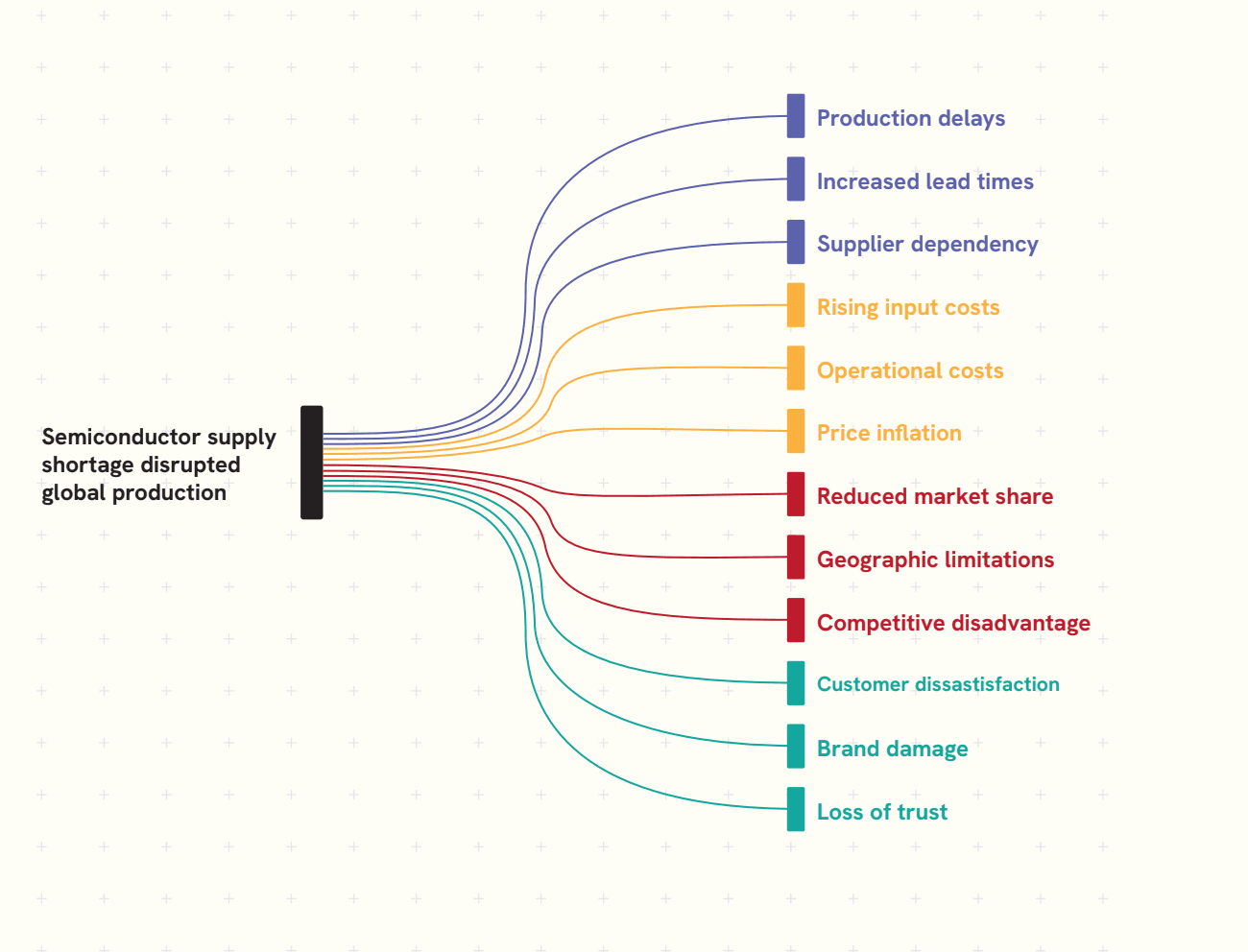
The report illustrates this with a detailed example from the 2021 semiconductor shortage. While the dominant narrative centred on automakers, the real impact was far more diffuse. Supply constraints surfaced in unexpected places: medical device manufacturers flagged component delays, industrial firms reported production bottlenecks, and niche manufacturers faced disruptions that were largely absent from headline coverage.
By constructing a dataset around the theme of “production delays,” the analysis was able to capture these second-order effects across sectors, something no pre-existing dataset was built to do. The result was not just a richer description of the event, but a systematic signal with clear cross-sectional structure.
The new research stack
This shift doesn’t replace structured data, instead it extends it. Structured datasets remain essential for scale, consistency, and broad market coverage. What’s changing is how they are complemented.
Microdatasets introduce precision and flexibility, allowing researchers to go deeper where it matters most. Together, they form a more complete research stack: one that combines stable, scalable foundations with the ability to rapidly explore new ideas.
At the centre of this evolution is control. The compression layer (the point where raw information is transformed into a usable signal) is moving closer to the researcher. It is becoming faster to iterate, more responsive to new hypotheses, and increasingly defined by the user rather than fixed in advance.
Explore the full framework
This post is an introduction. The full report goes deeper into:
The end-to-end microdataset construction pipeline
Techniques like Smart Batching and Smart Sampling
A full worked example with methodology and results
Practical considerations for building signals from raw content
Download “From Dataset Consumer to Dataset Creator” to see how this approach can fit into your research workflow.


