Architecting Bigdata.com search: advanced dimensions and synthesis
July 2025•Ricard Matas Navarro, Director of Search & Retrieval @ RavenPack | Bigdata.com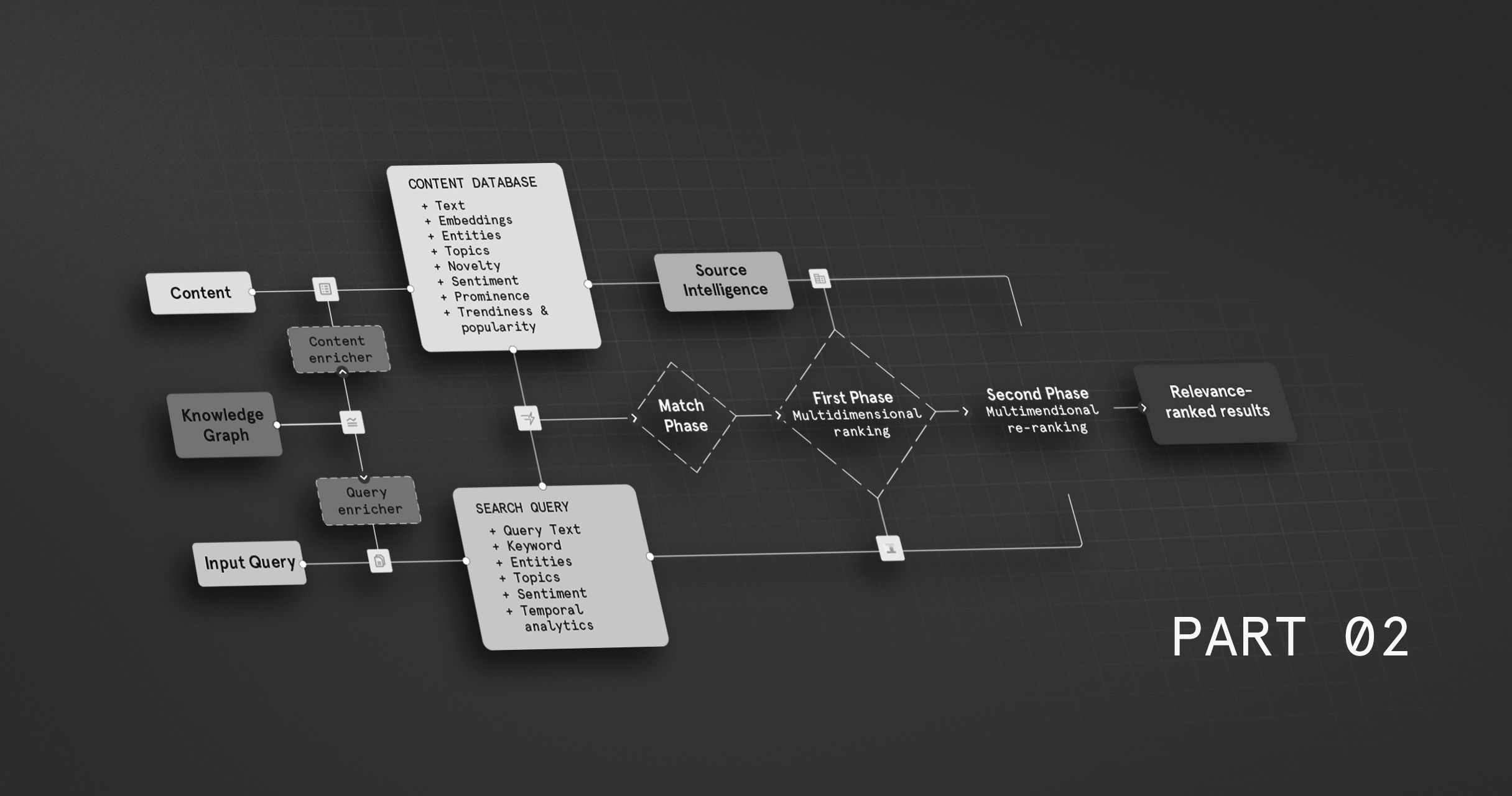
This follow-up explores Source Intelligence, Novelty Detection, and Contextual Analytics within the system.
This article was initially published on Medium.
In a previous article, I discussed the importance of advanced search, introduced the foundational principles of Bigdata.com’s multidimensional framework, and examined its Deep Semantics and Knowledge Graph components. In this continuation, I explore additional key dimensions — Source Intelligence, Novelty Detection, and Contextual Analytics — and how they are synthesized within the broader system.
Source intelligence: understanding provenance and expertise
In domains driven by information flows, such as news and financial research, understanding where the information is coming from is paramount. A simple relevance score is incomplete without considering the credibility and expertise of the source. RavenPack integrates source intelligence as a key dimension:
Generic trustworthiness:
The framework incorporates baseline source credibility scores. These scores can be derived from assessing relatively static attributes associated with journalistic quality and reliability, such as indicators of accountability, reporting standards, and historical reliability. While challenging to quantify universally, establishing tiers or scores based on observable characteristics provides a foundational layer of trust assessment.
Topic-specific authority modeling:
Recognizing that a source’s credibility is often context-dependent, Bigdata.com implements a more dynamic, topic-aware layer.
Source Network Analysis: By analyzing vast historical publication data, the system maps how information flows between sources. Similar to social network analysis, this can help identify original information creators versus distributors or replicators, and understand the influence and reach of different sources.
Domain Expertise Clustering: Based on historical coverage patterns (what topics a source frequently covers and with what depth), sources are clustered into groups representing specific areas of expertise (e.g., sources specializing in macroeconomic analysis, equity research, technology sector news, political commentary).
Dynamic Authority Adjustment: When a user query arrives, the system extracts the key topics or themes embedded in the query intent. The ranking model then dynamically adjusts the authority score assigned to each source based on the alignment between the query’s topics and the source’s demonstrated historical expertise and coverage depth in those specific topics.
By evaluating source expertise in the context of the user’s specific information need (as expressed through the query topic), the system delivers a more nuanced and relevant assessment of source quality.
Discerning the new: novelty and freshness
The sheer volume of information, particularly in the news cycle, leads to significant repetition and recirculation of content. A single piece of news can be echoed by hundreds of sources within hours, and older information is frequently cited for context in newer articles. Distinguishing genuinely new information from outdated content is crucial, especially in finance where market efficiency relies on the rapid incorporation of novel information: old news, even if recently republished, is generally considered already reflected in market prices and thus less valuable for generating alpha or making timely decisions. Bigdata.com explicitly addresses this through dedicated novelty and freshness signals.
Freshness refers simply to the recency of publication. Prioritizing fresh documents means favoring those published most recently, which can either bring new content or better scrutinized views of a certain topic. While useful for certain queries (e.g., “latest merger & acquisitions activity”), freshness alone is insufficient.
Novelty measures whether the information content within a document (or chunk) is substantially new compared to information already processed by the system from earlier documents, regardless of the publication date. A document published today can contain entirely non-novel information if it merely repeats yesterday’s news. Conversely, an older document might contain information that is novel relative to a specific query context if that information hasn’t been seen recently or in relation to that query.
During content ingestion and enrichment, RavenPack calculates information novelty scores that become part of the indexed analytics next to the chunks of text. These pre-computed scores are then used as a factor in the ranking algorithm. Documents or chunks containing genuinely novel information relevant to the query can be substantially boosted, helping users cut through the noise of repetitive content and find more important and impactful content.
The framework also acknowledges that the importance of freshness versus novelty can vary. The system allows for flexibility to adjust the weighting of freshness in the ranking formula depending on the user’s query. Sometimes, strict time-range filters combined with novelty scoring are more effective than a simple recency bias, especially when searching for specific historical novel events rather than just the latest updates.
Contextual analytics: adding further layers of relevance
Beyond core semantics, entities, sources, and novelty, Bigdata.com’s framework incorporates a range of contextual analytics to refine relevance scoring:
Document prominence
Not all mentions are created equal. The system analyzes how query-related information appears within a document to gauge its prominence:
Positional Features: Information appearing earlier in a document, particularly in the headline or lead paragraphs, is often considered more significant and receives higher weighting.
Frequency Features: The number of times query-related entities or concepts are mentioned, often normalized by document length or the frequency of other entities, can indicate focus.
Density/Distribution Features: How mentions are distributed throughout the document matters. Are they concentrated in one section, suggesting a specific sub-topic, or spread throughout, indicating the document’s main theme?
Structural Context: The relationship between the content match and the overall document structure is considered. For example, a semantic match within a paragraph might be deemed more relevant if the document’s headline is also highly relevant to the query, suggesting the entire article is pertinent (document-chunk coherence).
Sentiment as impactfulness
Bigdata.com employs a unique, finance-centric definition of sentiment. Rather than just measuring positive/negative polarity, our sentiment aims to quantify the impactfulness of news or events, reflecting the anticipated strength of market or economic reaction. This impact score, derived from analyzing language patterns associated with market-moving events, is indexed in the database at chunk level alongside other features. Sentiment is therefore not used for opinion mining but as a predictive relevance feature directly tied to financial significance.
Additionally, for queries where sentiment is explicitly relevant (not uncommon in finance and business intelligence, e.g., “find positive news about Company X’s”, “assess negative ESG exposure for Sector Y”), the system can extract this sentiment intent and use the indexed impactfulness scores to further filter or boost results.
Other query enrichment features
The initial user query undergoes sophisticated analysis to extract multiple layers of intent beyond simple keywords. Previously, we already discussed the Entity and Topic Extraction, identifying the core entities and event/topic categories is fundamental, as well as the Sentiment intent.
Additionally, we also extract Temporal Analytics. The system parses and normalizes temporal expressions, including absolute dates (“January 15, 2025”), relative times (“last week,” “yesterday”), and, crucially for finance, fiscal periods (“Q4 2025,” “FY 2024”). Recognizing fiscal periods requires domain-specific knowledge, as exemplified by Nvidia reporting “Q4 2025” results in February 2025 — a detail generic systems might miss.
Our commitment to privacy
It is important to note that RavenPack takes user confidentiality extremely seriously. The core search and ranking mechanisms do not utilize any personally identifiable information, user location data, or search history from previous sessions. In Bigdata.com, query reformulation occurs within a single chat session context but it is handled by an external planner that can create multiple parallel and/or consecutive search requests in order to formulate a better answer. The search engine itself operates on the immediate query without leveraging cross-session user context.
Synthesizing intelligence: the multi-stage ranking engine
Bringing together these diverse signals requires a sophisticated ranking architecture capable of balancing the need for speed across billions of documents with the depth required for high-precision results. RavenPack employs a multi-stage ranking approach.
Stage 1: Matching / Candidate Generation
This initial stage operates over the entire indexed corpus (potentially billions of documents). Its goal is high recall — ensuring that potentially relevant documents are not missed. It focuses on fast approximate hybrid search (semantic and lexical) combined with analytics matching (entities, time periods, etc.).
Stage 2: First Phase Ranking
The candidate set from Stage 1 is passed to a fast, but more discriminating, ranking model. This stage incorporates a richer set of features than Stage 1, such as more precise vector similarity scores, source intelligence scores, freshness indicators, document prominence and sentiment. Its goal is to significantly improve precision by scoring and re-ordering the candidates, reducing the set to perhaps a few hundred documents.
Stage 3: Second Phase Reranking
The final stage applies the most computationally intensive models and features to the small set of top candidates from Stage 2. This is where the cross-encoders come into play, still in combination with the other ranking features from the first phase that are not captured by a semantic model. The goal of this stage is high precision at the very top of the ranked list, ensuring the final results presented to the user or fed to an LLM are the most relevant and reliable.
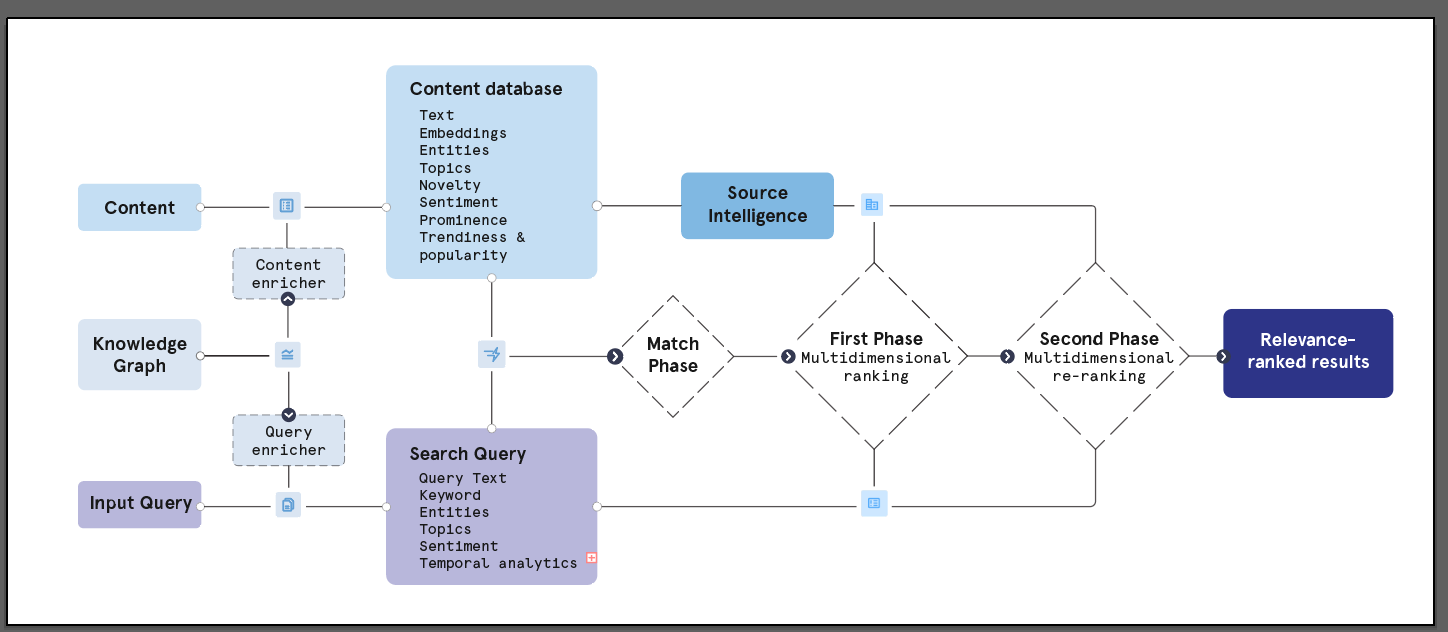
Feature integration summary:
The power of this architecture lies in its ability to ingest and synthesize signals from all the dimensions discussed previously. The final ranking models learn to weigh and combine a rich feature set, including:
- Lexical scores: BM25, Vespa nativeRank.
- Semantic scores: Fine-tuned embedding similarity (bi-encoder), cross-encoder relevance scores, topic/event matching scores.
- KG-driven features: Precise entity matching flags, entity type information, potentially related entity signals.
- Source intelligence: Baseline trustworthiness, dynamic topic-specific authority scores.
- Novelty & freshness signals: Information novelty scores, publication date/recency.
- Sentiment: Document/chunk sentiment scores (direction and magnitude).
- Document analytics: Positional features, frequency/density metrics, document/chunk quality indicators (readability, coherence).
- Temporal analytics: Matching of specific dates, relative times, and fiscal periods.
Conclusion: architecting the future of search
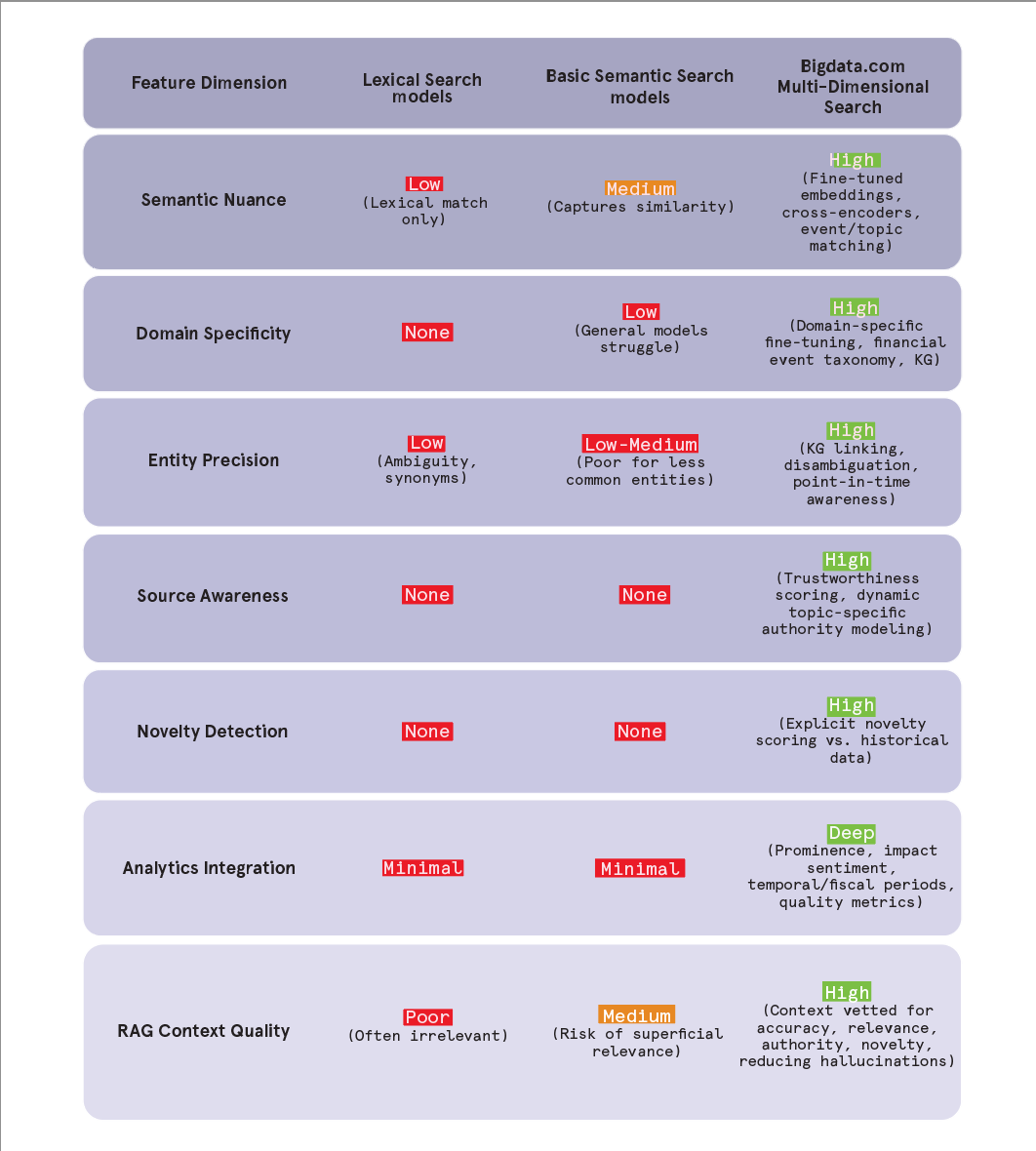
The generative power of Large Language Models continues to capture the popular imagination. Yet, as the underlying models trend towards commoditization, the enduring challenge and the critical differentiator for creating truly impactful and reliable AI applications shift to the intelligent access, retrieval, and evaluation of information.
Simple keyword search is demonstrably obsolete for complex tasks, and basic semantic similarity, while an improvement, proves insufficient in the face of domain specificity, entity ambiguity, and the need for trustworthy, novel insights. Bigdata.com’s advanced search framework represents a new frontier in information retrieval. By integrating multiple dimensions — deep semantic understanding powered by domain-specific models and cross-encoders, precise entity grounding via a comprehensive Knowledge Graph, dynamic source intelligence, sophisticated novelty detection, and rich contextual analytics — it moves beyond mere similarity matching. This is engineered intelligence retrieval, designed to surface information that is not only relevant but also accurate, timely, authoritative, and genuinely insightful.
And we know things don’t stop when you retrieve the results, this is just the first step for a lot of downstream tasks that will use that information, for example as the context fed to a LLM. This is why users of our search API don’t only receive the textual outputs but also many of the enrichments we use for the search, such as source information, entity or event detections and sentiment scores.
This multi-dimensional approach provides the foundation to unlock the potential of LLMs, particularly in demanding fields like finance where information quality is paramount. It mitigates the risks associated with feeding AI models with low-grade context, paving the way for more reliable and valuable AI-driven solutions. With over two decades of focused expertise and continuous innovation in NLP for finance, RavenPack is not just indexing the world’s information; we are building the systems to understand it.
To see our approach in action, we invite you to explore the Bigdata.com platform documentation and request an API key.