By
By Ricard Matas Navarro, Director of Search & Retrieval @ RavenPack | Bigdata.com
·

This article was initially published on Medium.
As Large Language Models (LLMs) become increasingly powerful yet commoditized, the true differentiator for impactful AI applications drifts from the models themselves to the quality and sophistication of the underlying information retrieval systems. Traditional keyword search and basic semantic similarity approaches are insufficient for complex domains like finance, often failing to capture nuance, handle domain-specific language, verify source credibility, or discern information novelty. This limitation becomes critical in Retrieval-Augmented Generation (RAG) systems, where low-quality retrieved content leads to unreliable or misleading LLM outputs.
Bigdata.com addresses these challenges with an advanced, multi-dimensional search framework designed for engineered intelligence retrieval. Leveraging over two decades of financial NLP expertise, our architecture moves beyond simple similarity to synthesize signals across multiple layers:
Deep Semantics: Utilizing domain-fine-tuned embeddings, cross-encoder reranking and proprietary event/topic taxonomies.
Knowledge Graph (KG) Grounding: Employing precise entity linking and disambiguation against a vast, point-in-time aware financial KG.
Source Intelligence: Assessing source credibility and dynamically modeling topic-specific authority.
Novelty & Freshness: Distinguishing genuinely new information using dedicated scoring.
Contextual Analytics: Incorporating signals like document prominence, financial sentiment (impactfulness), and query intent analysis.
Powered by scalable infrastructure, this multi-stage ranking framework provides the high-quality and trustworthy information foundation necessary for reliable RAG systems and dependable AI-driven financial analysis. It represents the state-of-the-art, defining the frontier where search evolves into true intelligence retrieval.
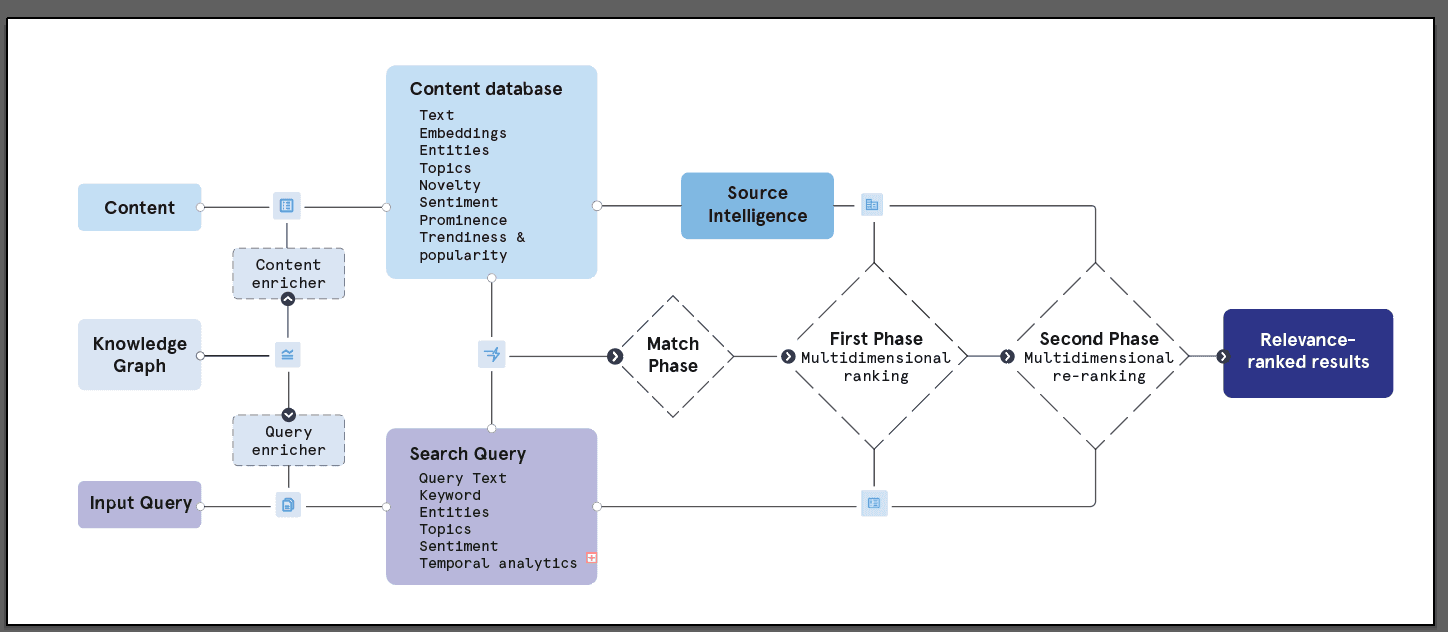
Bigdata.com's multi-stage ranking framework
Beyond the Headlines — Search Quality is what really matters
The current technological landscape is captivated by the advancements in Large Language Models (LLMs) and their remarkable generative capabilities. This fascination is understandable; models that can converse, summarize, and create content represent a significant leap. However, this focus often overshadows a more fundamental truth: the ultimate utility of these powerful models, especially in high-stakes environments like finance, is dictated not just by their generative mastery but by the quality, relevance, and trustworthiness of the information they access.
A compelling analogy gaining traction is that “LLMs are the new SQL”. Just as SQL (Structured Query Language) became the standard interface for interacting with relational databases, enabling countless applications, LLMs are becoming the new interface for interacting with vast amounts of information and executing complex instructions via natural language. Thousands of valuable startups and applications are being built on top of foundational LLM capabilities, much like the software ecosystem that grew around SQL databases.
This parallel can be extended further. Core SQL database technology eventually became commoditized infrastructure. Similarly, the foundational capabilities of LLMs are rapidly heading towards commoditization. Fierce competition among major players, the rise of powerful open-source alternatives and aggressively falling inference costs are driving this trend. This commoditization fundamentally shifts the landscape of value creation. As the base models become more interchangeable and accessible, the sustainable competitive advantage and economic value migrate “up the stack” to the layers built upon them.
Consequently, maintaining a competitive advantage in the AI era cannot rely solely on leveraging a base LLM. Simple “wrapper” applications that only put a thin interface over a standard LLM are inherently vulnerable. True, defensible value is being created by companies that integrate LLMs deeply into specific workflows, leverage proprietary data, build unique user experiences, understand domain nuances, and solve specific customer problems more effectively than a general-purpose model can alone. Moats are built through specialization, integration, data advantages, superior user experience, and execution excellence.
In this evolving ecosystem, LLMs are transitioning into:
Execution Engines: Core compute layers that take our intent-rich, natural language queries and translate them into precise data operations or workflows over specific domains. Bigdata.com’s APIs streamline these execution workflows across a wide array of datasets and analytics.
Syntax Layers: Intuitive, conversational interfaces built atop deeper layers of semantic understanding and structured knowledge. The chat interface in Bigdata.com makes complex data exploration as simple as asking a question.
Commodity Gateways: Standardized ports into proprietary relevance models, curated datasets, and specialized analytical capabilities — enabling marketplaces like Bigdata.com to provide specialized capabilities as plug-and-play services.
Recognizing this paradigm shift, RavenPack, leveraging over two decades of expertise in applied NLP for the demanding financial sector, has invested heavily in architecting a search and retrieval framework that transcends conventional limitations. This framework moves beyond simple keyword matching or basic similarity to deliver what can be termed engineered intelligence retrieval. It is designed to feed downstream applications, including LLMs, with information characterized by its depth, accuracy, and contextual understanding. This document provides a brief exposition of the current state of this framework, which never stops evolving and improving, detailing some of the key components that enable a superior performance, particularly within complex domains like financial news analysis and document intelligence.
Why Similarity falls short in Search
The journey of Information Retrieval (IR) has seen significant evolution, yet conventional approaches exhibit fundamental cracks, especially when applied to complex domains.
Early IR systems predominantly relied on lexical matching techniques like TF-IDF (Term Frequency-Inverse Document Frequency) or foundational probabilistic models such as Okapi BM25. These “bag-of-words” methods treat documents as collections of keywords, calculating relevance based on word frequencies and distribution. While effective for their time and still useful as components in modern systems, they inherently struggle with the subtleties of human language: semantic nuance, synonymy, polysemy (the same word having multiple meanings), and overall conceptual understanding are largely lost.
The advent of vector embeddings, generated by models like Word2Vec, GloVe, and more recently, large transformer-based language models, marked a significant leap forward. Representing text as numerical vectors in a high-dimensional space allows for “semantic search,” where relevance is determined by the proximity (often measured by cosine similarity) of query and document vectors.
However, even standard semantic search, while powerful, often falls short:
The “Question is Not the Answer” Problem: A user’s query and the text containing the answer might be conceptually related but use very different vocabulary or phrasing. Consequently, they may not be close neighbors in a general-purpose embedding space, leading to missed relevant results.
The Domain Specificity Trade-off: A critical limitation arises from the training data of embedding models. While general-purpose models, trained on vast, diverse web corpora, offer broad applicability, they demonstrably struggle to capture the specific linguistic patterns, jargon, and semantic nuances of specialized domains. A model’s strong performance on general benchmarks does not guarantee a comparable performance in a domain like finance. This highlights the need for domain-specific evaluation and the potential benefits of domain-adapted models. Domain adaptation through techniques like fine-tuning can enhance the performance within the target domain; however, an increased focus on a specific domain may lead to a decrease in the model’s ability to generalize to other contexts. This trade-off between specificity and broader applicability must be carefully considered.
Entity Handling Issues: Embeddings, because they focus on semantics, are not necessarily good with named entities, where the meaning of the corresponding words often has no relationship to the entity itself. While very common entities might be well-represented due to frequent co-occurrence with relevant terms in training data, less common entities are often poorly handled. This necessitates complementary approaches like keyword search or, more robustly, entity linking systems.
Ignoring Critical Dimensions: Basic semantic search doesn’t account for other dimensions of importance, such as the credibility and topical authority of the information source or freshness of the content; critical aspects when performing a search over billions of documents coming from thousands of different sources.
These limitations become particularly accentuated in Retrieval-Augmented Generation (RAG) systems. RAG aims to improve LLM outputs by grounding them in retrieved information. However, if the retrieval component provides context that is merely superficially similar but ultimately low-quality, irrelevant, outdated, factually incorrect, or from an untrustworthy source, the LLM is likely to produce suboptimal, misleading, or outright “hallucinated” responses. The quality of the retrieval pipeline directly dictates the quality and reliability of the RAG output.
Bigdata.com’s framework is explicitly architected to address these deficiencies, moving beyond simple similarity to a multi-dimensional understanding of relevance.
Bigdata.com’s Multi-Dimensional Framework
The core principle underpinning Bigdata.com’s search architecture is that true relevance in complex domains is not a single score but a multi-faceted construct. It requires synthesizing diverse signals spanning deep semantic understanding, precise entity identification grounded in a knowledge graph, assessment of source intelligence, discernment of information novelty and analysis of other contextual factors. This approach leverages RavenPack’s extensive infrastructure, which processes millions of documents daily from thousands of sources, enriching them with these crucial dimensions in real-time and across a deep historical archive.
1. Deep Semantics: Beyond Basic Similarity
Achieving genuine semantic understanding requires moving beyond simple vector closeness in a generic space. Bigdata.com employs a multi-layered approach:
First layer: Fine-Tuned Semantic Matching
The foundation is built on vector embeddings, but these are not off-the-shelf general-purpose models. RavenPack utilizes embedding models that have been fine-tuned for the financial domain, using techniques like contrastive learning on question-answer pairs and domain-specific corpora. This ensures the embeddings better capture the nuances of financial language and concepts than generic models.
Second layer: Event/Topic-Driven Semantics
RavenPack leverages its proprietary Topic Detection technology, built over 20 years in finance, as another powerful semantic layer. This system identifies mentions of specific, market-moving events within text, drawing from a detailed taxonomy of over 7,000 event categories covering business, geopolitical, macroeconomic, and ESG themes. The search framework extracts relevant events and topics from the user’s query, analyzing their intent. These are then matched against the events and topics pre-indexed in RavenPack’s vast content database, allowing for fast and precise matching and boosting. This provides a highly structured, granular, and finance-centric layer of semantic matching that complements the vector-based approaches.
Third layer: Semantic Reranking with Cross-Encoders
While fine-tuned bi-encoder embeddings (where query and document are encoded separately) are efficient for initial retrieval from billions of documents, higher accuracy can be achieved using cross-encoders in a subsequent reranking stage. Unlike bi-encoders, cross-encoders process the query and a candidate document together, allowing the model to perform deep, token-level interaction analysis. This joint encoding captures much finer-grained semantic relationships and relevance signals than comparing pre-computed, independent vectors, leading to superior ranking accuracy. The trade-off is computational cost, hence why this step is employed in a later stage to rerank a smaller set of promising candidates retrieved by the faster initial stages.
Other advanced considerations
Building effective semantic search involves more than just choosing an embedding model. Significant engineering effort goes into optimizing text chunking — the process of breaking large documents into smaller pieces for embedding and retrieval. Handling context across chunk boundaries and mitigating biases introduced by chunking are further complexities that require careful study, often overlooked in the current “ship fast or die” market environment.
Our framework also incorporates multiple embeddings, potentially specialized for different content granularities or semantic aspects. For instance, separate embeddings are used for headlines and body text, recognizing that news headlines often carry condensed, high-impact information that can move financial markets. Comparing chunk embeddings to headline embeddings is useful to identify the chunks most relevant to the main topic announced in the headline, allowing for more targeted context retrieval.
Our sophisticated semantic matching is powered by Vespa.ai, a high-performance and flexible platform for AI-driven applications. RavenPack adopted Vespa in 2020 — yes, well before the boom of the LLMs — and leverages its capabilities for billion-scale vector search for speed and accuracy across vast datasets.
2. Knowledge Graph-Powered Entity Linking
Semantic understanding alone is insufficient, particularly when dealing with specific real-world entities. Bigdata.com enhances its search capabilities through a sophisticated entity linking system built upon a massive Knowledge Graph (KG).
The process starts with RavenPack’s Named Entity Recognition (NER) system, which identifies mentions of entities within both user queries and the indexed documents. This system recognizes over 30 distinct entity types relevant to finance and business.
These mentions are then linked to the RavenPack Knowledge Graph (KG), a proprietary, continuously updated repository containing canonical representations of over 12 million unique entities, including global companies (public and private), executives, places, organizations, products, and more. A critical feature, especially for finance, is the KG’s point-in-time awareness. It tracks entities and their identifiers (like tickers or CUSIPs) as they exist at specific moments, crucial for handling historical analysis correctly and avoiding survivorship bias when company names change or entities merge.
The Entity Linking and Disambiguation step connects the textual mentions identified by NER to their unique, canonical nodes in the KG. This resolves ambiguity — ensuring “Apple” refers to the technology company, not the fruit — and grounds the search in concrete, real-world concepts. Techniques like co-reference resolution are also employed to link pronouns and other references back to the correct entity within a document.
This KG-driven entity linking provides several crucial advantages for search:
It overcomes the inherent weakness of pure semantic or keyword approaches in precisely identifying specific entities, especially less common ones whose names might lack strong semantic signal or be ambiguous. The example of searching for “latest rumours about funding rounds for company A” illustrates this: KG-linking prevents retrieving results about “company B” even if the surrounding text is semantically similar, because the system filters for documents explicitly linked to the canonical representation of “company A”.
The KG stores numerous aliases and identifiers for each entity (e.g., legal names, common names, stock tickers, former names). This allows the system to find relevant documents even when the entity is mentioned in varied ways, improving recall compared to matching only a single name or keyword. Examples of this go beyond simple alias detections: from detecting “Elon Musk” as “Tesla CEO” to injecting an “Alphabet Inc” detection when “Waymo” is mentioned.
Because entity mentions are detected and linked to the KG during the initial document processing (enrichment) phase, these links can be indexed. This allows the search engine to rapidly filter the massive document corpus down to only those documents known to contain the specific entity (or entities) mentioned in the query, speeding up subsequent semantic analysis or ranking stages.
In addition to Deep Semantics and Knowledge Graph grounding, Bigdata.com’s framework integrates several other key signals — including Source Intelligence, Novelty Detection, and Contextual Analytics- which will be explored in the second part of this exposition.
To see our approach in action, we invite you to explore the Bigdata.com platform documentation and request an API key.


