How we used Large Reasoning Models with Grounding to build Dynamic Mind Maps
July 2025•Alessandro Bouchs, Senior Data Scientist & Quant Researcher
We explain how we moved from using basic language models for simple mind maps to leveraging advanced Large Reasoning Models (LRMs) with grounding.
A core focus of our recent work has been using LLMs to replicate and scale the reasoning process of seasoned financial analysts, particularly through Chain of Thought-based agentic workflows.
We started with a simple question: How do we find all companies exposed to a given theme, narrative, or risk scenario?
Answering this isn’t straightforward. It requires breaking broad themes into their component parts and unpacking risk scenarios into specific consequences and exposures.
While experienced analysts rely on domain expertise and their analytical frameworks to do this, the process is quite time-consuming and manual for most users.
So instead of investing hours per theme every time, we chose to spend those hours building a robust agentic workflow. One that could safely mimic the work of an analyst across any theme, at scale.
A foundational tool in this process is the mind map. Mind maps allow for the accurate and comprehensive decomposition of a concept into sub-themes and narrative threads. They explicitly encode the analyst’s structured thinking, enabling our agents to reason over each sub-component individually while maintaining the integrity of the overarching theme.
Mind maps serve as the schema that underpins our Agentic Retrieval-Augmented Generation (RAG) systems. Each node in the mind map corresponds to a specific risk, scenario, or thematic subspace, and provides a definitional anchor for the generation of example queries, constraints, or classification targets. By working with these smaller and semantically precise units, our vector retrieval becomes significantly more targeted: we improve recall by surfacing relevant but diverse signals, and we improve precision by avoiding the ambiguity and generality often associated with broader topics. This decomposition also enhances explainability by making the agent’s reasoning traceable. In this way, mind maps provide the conceptual structure within which search, classification, and reasoning tasks can operate effectively. They support modular, interpretable workflows that scale across an expanding set of themes, risks, and narratives.
Building the first mind map: low-sost models, basic risks
The first step was to tap into an LLM’s built-in knowledge to accelerate the process. We asked a fast and low-cost LLM (OpenAI 4o-mini) to break down a risk scenario using the following instructions:
The model returned this mind map:
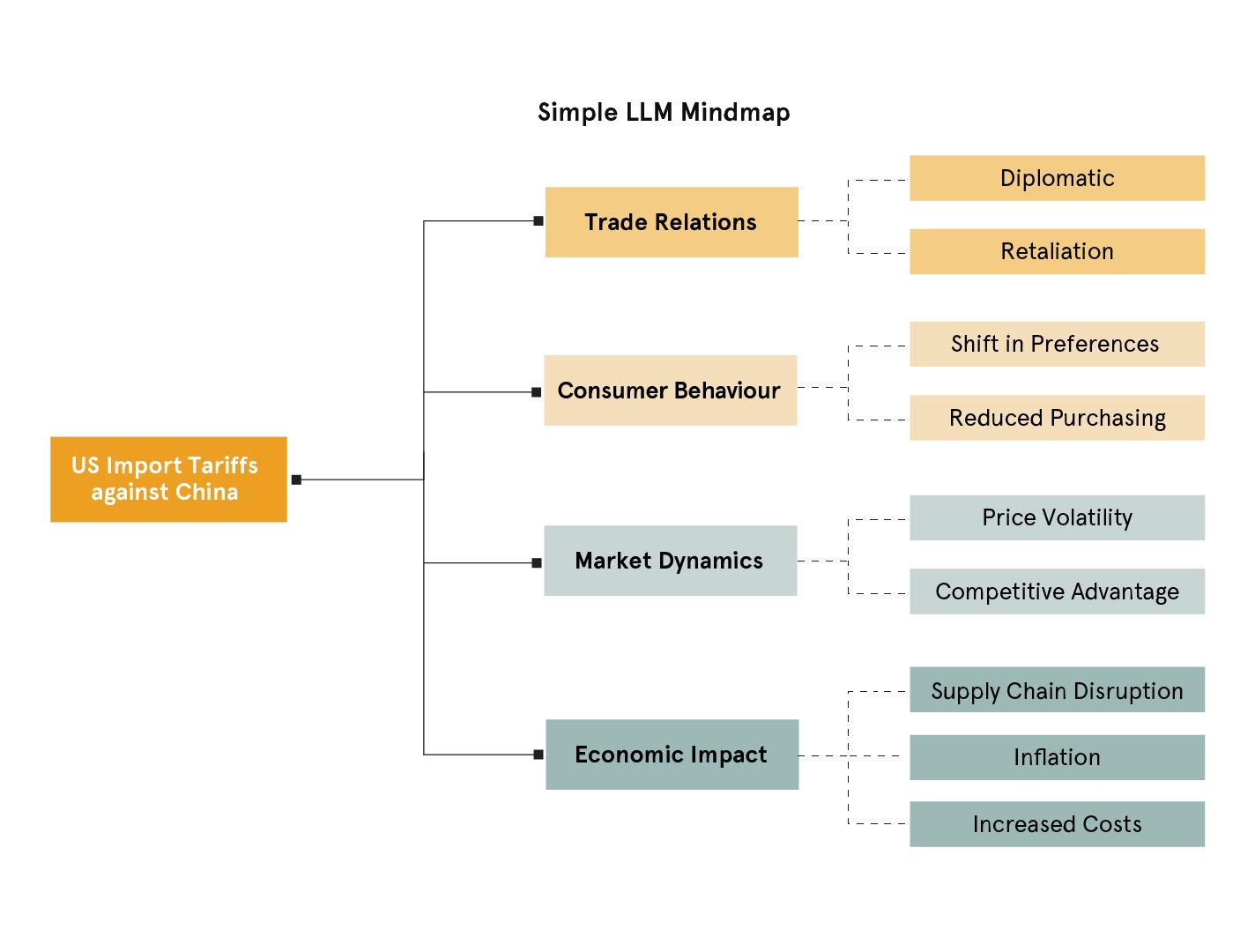
This result covers the fundamentals, but you can likely tell it’s quite narrow in scope, and it lacks structure. Crucial risk factors, such as supply chain disruptions, are considered sub-scenarios, and the categories are quite generic.
This is where a seasoned analyst would say, “I can do better than this,” and they’d be right. But today, you can prompt the LLM to perform more like an analyst using a human-in-the-loop approach. In our agents, we always allow users to inject additional instructions, context, or constraints using a focus parameter. In this case, we added the following focus to the original instructions:
The same model then returned this mind map:
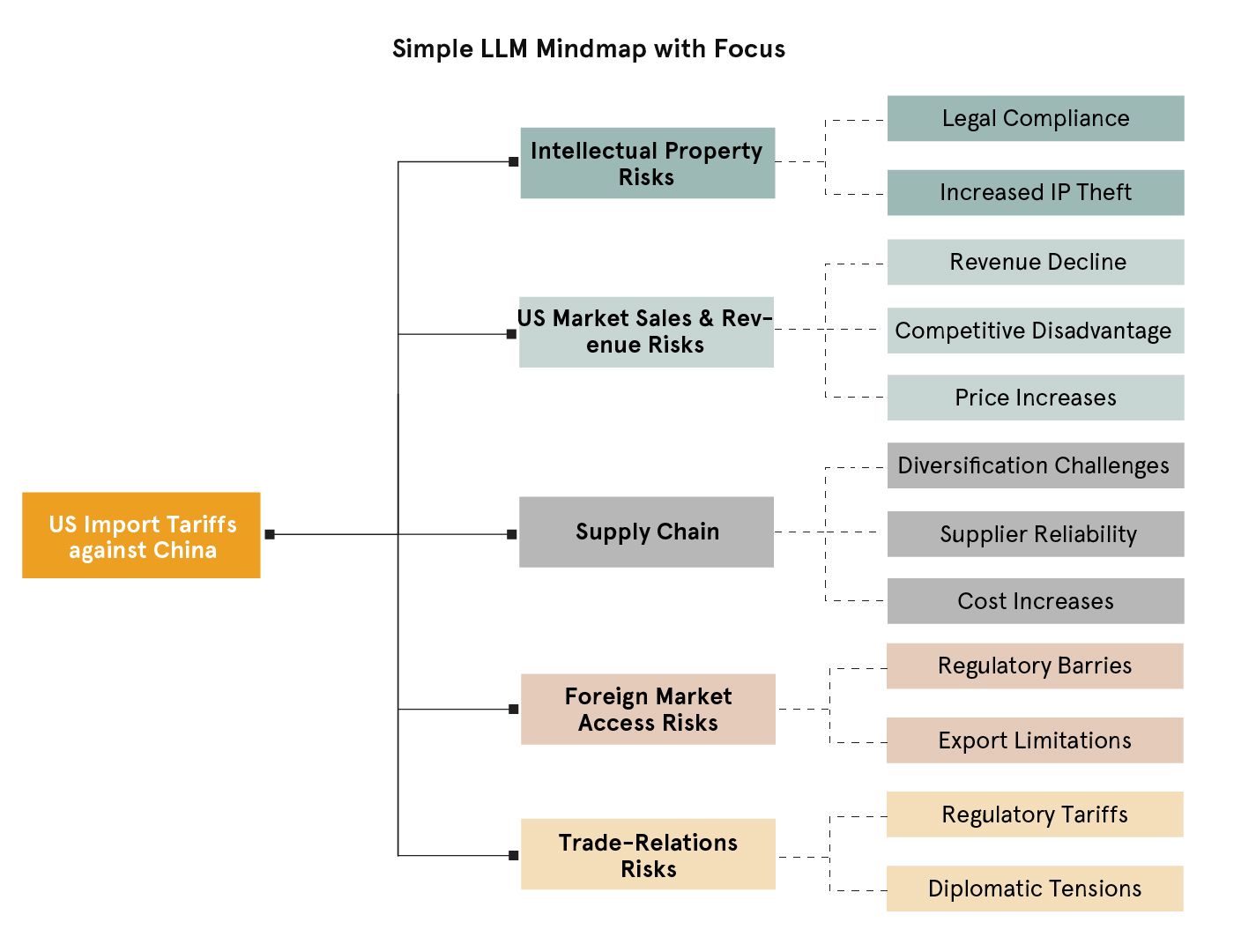
At this point, the model is thinking more like us. But you may notice that it still doesn’t go beyond the risks we explicitly asked it to include. It’s constrained by the structure we imposed, and it doesn’t proactively surface other emerging or adjacent risks.
So what’s the next step? How do we design a system that:
- Covers our known priorities,
- Allows room for discovery, and
- Doesn’t require overly complex or fragile prompts?
Of course, we can improve our prompt design or build multi-step workflows using the same LLM. In fact, our current Research Toolkit uses a two-step refinement process and detailed prompts ranging from 25 to 50 lines. But these approaches come with overhead. Prompts can become difficult to maintain, and process complexity increases as themes diversify.
Reasoning matters: how Large Reasoning Models add depth and breadth
While basic LLMs follow the structure we give them, Large Reasoning Models (LRMs) can plan and extend the structure themselves. They are optimized for tasks that involve decomposing a prompt into parts, organizing thoughts, and producing deeper, more coherent outputs. This makes them ideal when we want to go beyond checklist prompts and surface adjacent, unprompted risks.
Although a single API call won’t give us a complete deep research pipeline, we can take a meaningful first step by prompting a large reasoning model (GPT o3-mini) with both the instructions and focus in a single shot.
The result? The mind map generated by the LRM showed clear improvements. It had greater breadth and a very clear structure, expanding every risk factor into at least two sub-scenarios consistently. Notably, the model added four entirely new risk types, Regulatory & Compliance, Operational, Financial, and Competitive, despite us not mentioning them explicitly, indicating its ability to explore adjacent and relevant dimensions.
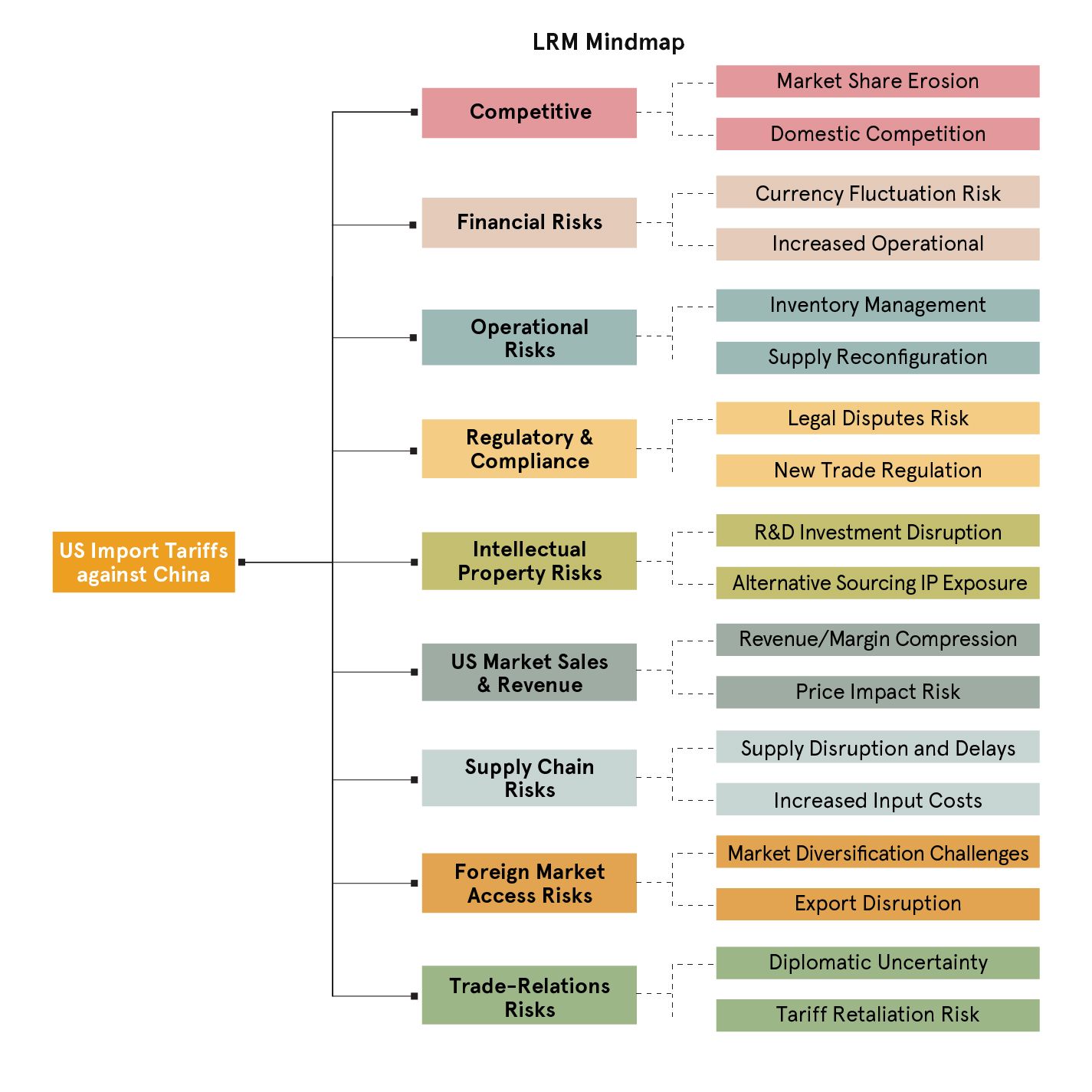
However, LRMs still rely on their knowledge, which may be outdated. Some of the risk factors listed may not be relevant for the specific Import Tariffs scenario that we are investigating. What if we wanted the mind map to reflect current events, evolving narratives, or newly emerging risks?
Grounding the map: tying risk narratives to real-world signals
We equipped the LRM with tool calling and with access to our Bigdata Search API. This allows it to query and ingest real-time content to inform its output.
Effectively, we combined the main capabilities or LRMs, planning, reasoning, tool use, and long-context processing, into a lightweight agent: the Deep Mind Map Generator.
Here’s how the process works:
- The LRM receives the base instructions, a theme, and a focus.
- It formulates search questions to enhance its own understanding.
- These questions are used to retrieve 20 relevant news chunks from the past 30 days via the Bigdata Search API.
- The LRM then processes this real-time news data, integrates it with prior reasoning, and generates a refined mind map.
Launching this process once returned the following result:
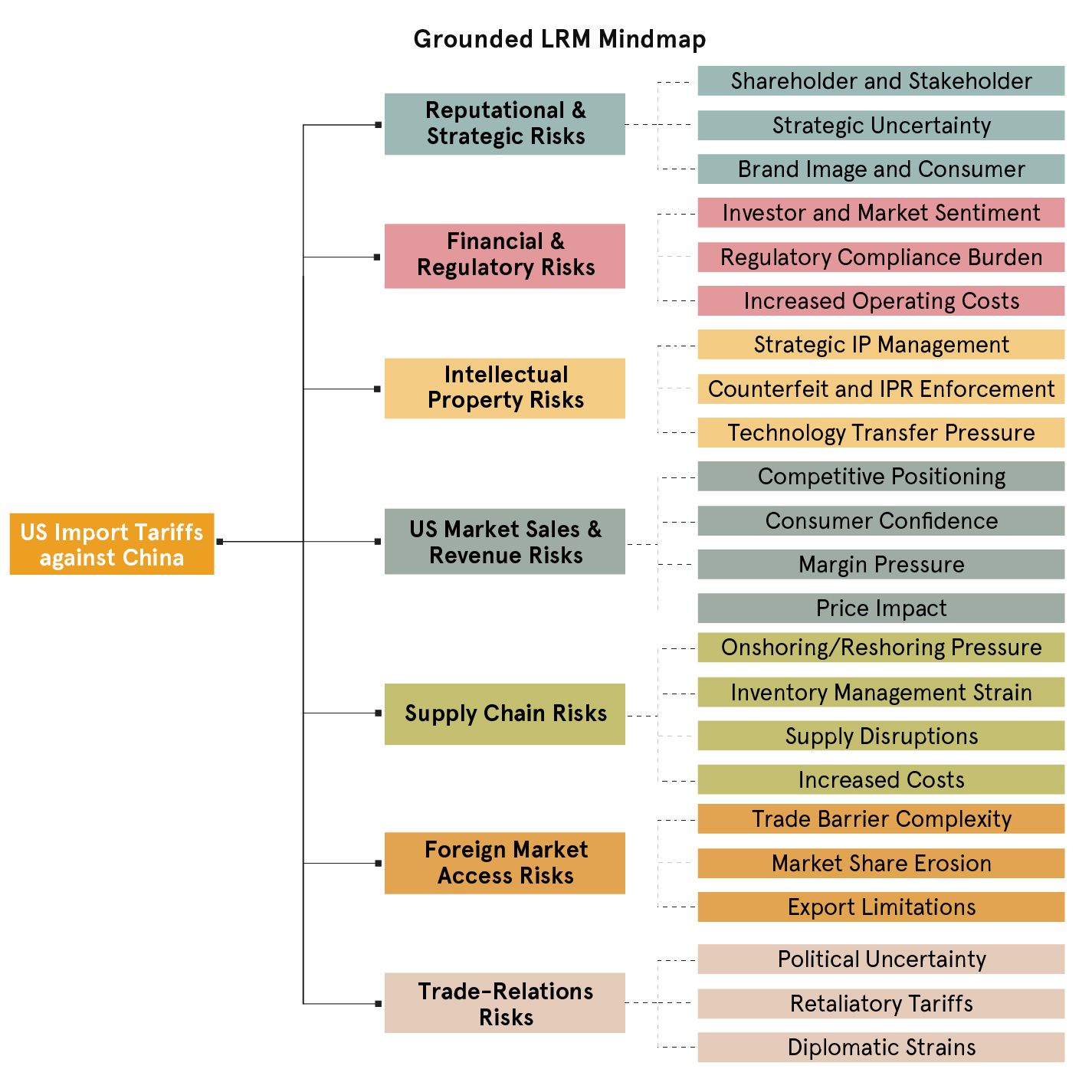
We can see that grounding the LRM in recent news data generated a mind map that has slightly less breadth, but more depth, as there are at least three sub-branches for each risk factor. For instance:
- Trade-relation risks / political uncertainty: The LRM correctly identified that sudden shifts in the policy stance on tariffs can cause serious short-term disruptions.
- Reputational & strategic risks: The model recognized that companies that are now relying on foreign manufacturing could face backlash and listed it as a potential sub-scenario.
- Financial & regulatory risks: In particular, the model picked up interesting narratives about Market investors and consumer sentiment
Checking the audit trail of the agent, we can see that the LRM ran the following searches on Bigdata API:
'US import tariffs against China short term impact on trade relations and supply chain risks',
'Impact of American tariffs on US companies foreign market access and revenue risks',
'US market price impacts and consumer demand effects due to tariffs on Chinese goods',
'Intellectual property risks for US companies amid US-China tariff escalation',
'Financial and regulatory challenges for US companies from new tariffs on China',
'Reputational and strategic risks arising from US import tariffs against China'
We notice that the LRM used our focus to guide its reasoning and design its retrieval strategy, but it also added search queries on two additional risks. These branches aren’t just speculative; they are grounded in recent news. In the model’s context window, we found the following excerpts that directly informed the risk map:
This triggered a more important question: if the model can extend risk taxonomies based on real-time input, can we also use it to track how sub-narratives evolve? And most importantly, are the additional narratives being surfaced useful?
Tracking narrative evolution: dynamic Mind Maps over time
To investigate this, we ran a repeated process to generate monthly mind maps:
- Start with a baseline mind map generated using a fast and low-cost LLM.
- Ask the LRM to refine it, either using its internal knowledge or by grounding it via the Bigdata Search API.
- At the end of each month, feed the latest mind map to the LRM again, grounding it in news from the previous 30 days to produce an updated version.
To evaluate how relevant and timely these mind maps are, we used them as inputs for one of our Agents relying on Chain of Thought Reasoning: the RiskAnalyzer. This agent takes each sub-branch and searches for articles linking companies in a portfolio to those specific risks. This allows us to measure how many relevant matches each sub-branch generates in a practical, time-sensitive application using recent news content.
While we’re not measuring accuracy in the traditional sense, we treat narrative volume in company exposure as a strong proxy for relevance. If a company is associated with a scenario that cleanly maps back to one of our sub-branches, then the system is performing as intended, and the narrative can be considered relevant.
The chart below summarizes the outputs. Each new sub-branch is visualized in the month it first appears, with the main risk category preserved for context. Line thickness and bar width represent the relative volume of supporting news chunks for each sub-branch at a given time.

The dynamic mind maps introduced two new branches in December (Technology & R&D Risks and Workforce & Labour Risks), one in January (Geopolitical & Strategic Risks), and several new sub-branches in April. This was achieved simply by giving the LRM a baseline mind map and grounding it with a small sample of news content retrieved via the Bigdata Search API.
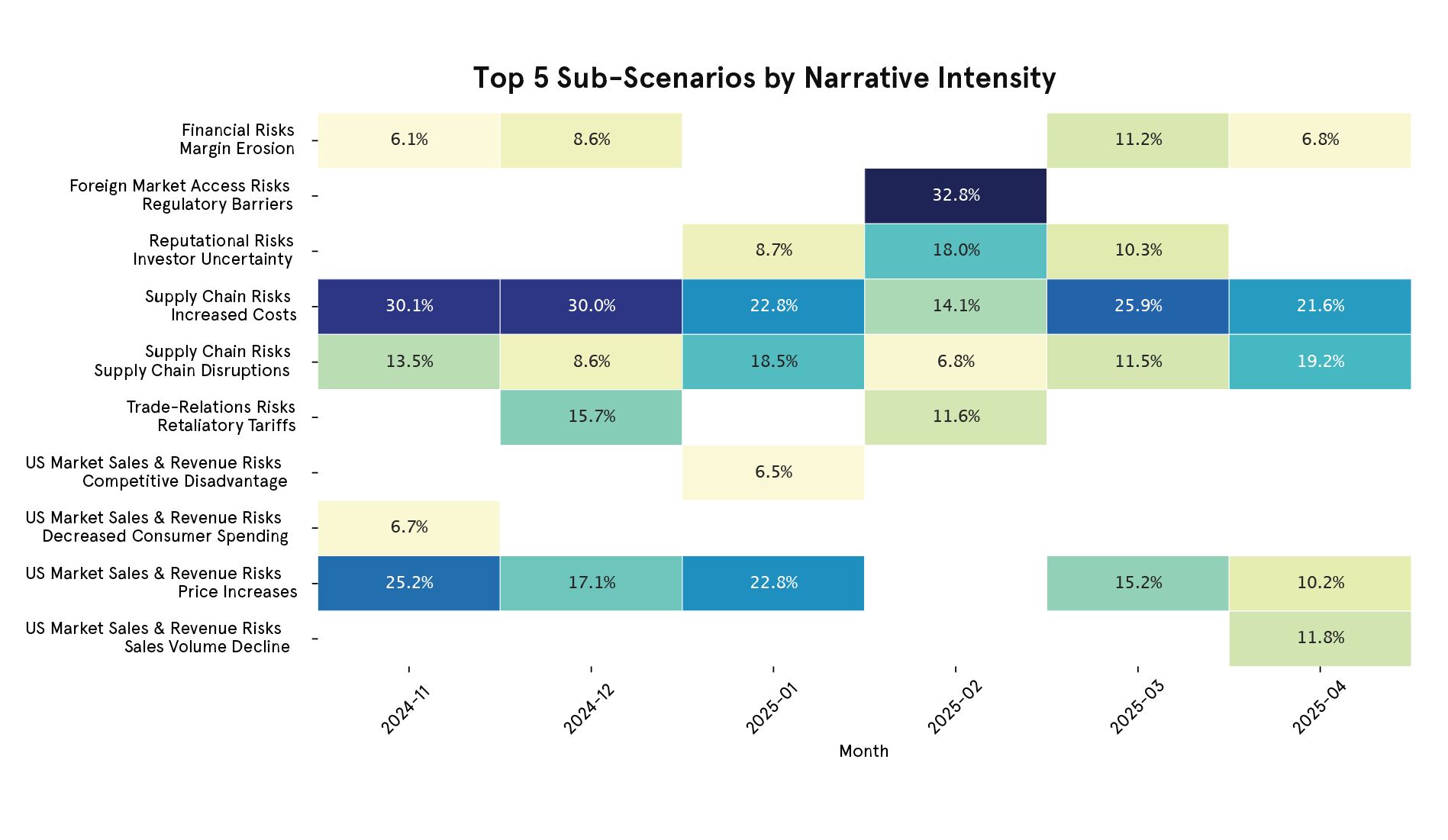
Some of the new sub-branches also emerged as significant narratives. For example, Geopolitical Risk / Policy Uncertainty ranked fourth in terms of narrative intensity in January 2025, and it remained relevant through March 2025, with a sustained hit count through our sample. The two new sub-branches added in April 2025 also feature among the top 5 for that month.
Through April, several major companies appeared as exposed to Policy Uncertainty, Supply Chain Risks, and Market-related Risks linked to tariffs. Below are some highlights from the news that the mind map helped uncover:
Closing the loop: how chain of thought agentic workflows stay current
Dynamic mind maps turn passive LLM outputs into self-updating analytical infrastructures, connecting reasoning, grounding, and validation into a feedback loop for decision-making.
When these dynamic mind maps are used to power agentic retrieval pipelines such as our Thematic Screeners and Risk Analyzers, they can help maintain an up-to-date view of emerging trends and continuously integrate new perspectives into the analysis.
We are already using mind maps to power our Thematic Watchlists, which offer a snapshot view of a portfolio’s exposure across different themes. With dynamic mind maps, these watchlists can also evolve in real-time, adjusting to new signals as the news flow changes.
Explore how Mind Maps power our Thematic Screeners at